Deploying LLMs on Amazon EKS using NVIDIA GPUs
Today I have deployed an LLM inference solution on Amazon EKS using NVidia GPU.
As part of my Generative AI hands-on learning, attended an AWS hands-on workshop, where I have deployed Mistral 7B Instruct v0.3 model using Ray Serve and vLLM on Amazon EKS.
Architecture
Below is the architecture diagram of the LLM inference solution I deployed on EKS.
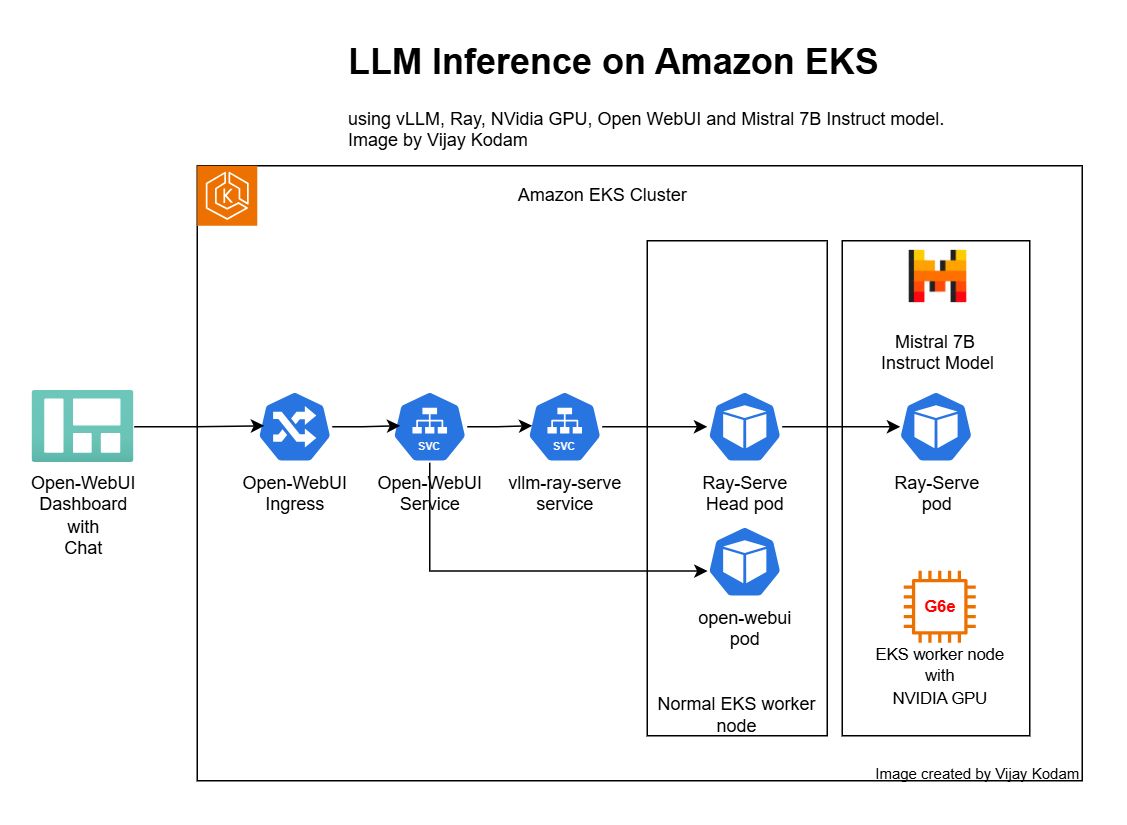
Components used
If you want to host your own models and control entire lifecycle for security or governance reasons then deploying LLM inference on Amazon EKS is a no-brainer.
Ray is one of the popular open-source frameworks for building and managing generative AI applications.
Ray Serve is a scalable model serving library for building online inference APIs.
vLLM is a popular high-throughput and memory-efficient inference and serving engine for LLMs. vLLM supports Kubernetes.
Used kuberay operator for deploying Ray. This operator handles all the complexity for you so I prefer this method for deploying Ray on K8s.
Ray dashboard provides visibility into overall cluster health, jobs, nodes etc.
Used Open WebUI for dashboard. Installed NVIDIA Data Center GPU Manager Exporter for monitoring NVIDIA GPU usage in Grafana.
Currently, AFAIK, for getting monitoring data from NVIDIA GPUs you have to install the NVIDIA DCGM exporter. It is straight-forward and exports needed metrics like GPU temperature, GPU Power usage, GPU utilization etc.
Conclusion
Ray, Open WebUI, vLLM, Mistral - All are open source software capable of scaling LLM inference very high. This is an exciting development for open source.
Follow Me
If you are new to my posts, I regularly post about AWS, Generative AI, LLMs, MCP, EKS, Kubernetes and Cloud computing related topics. Do follow me in LinkedIn and visit my dev.to posts. You can find all my previous blog posts in my blog